Bleacher Report - Emoji Is Life
Published on: 4/12/2018
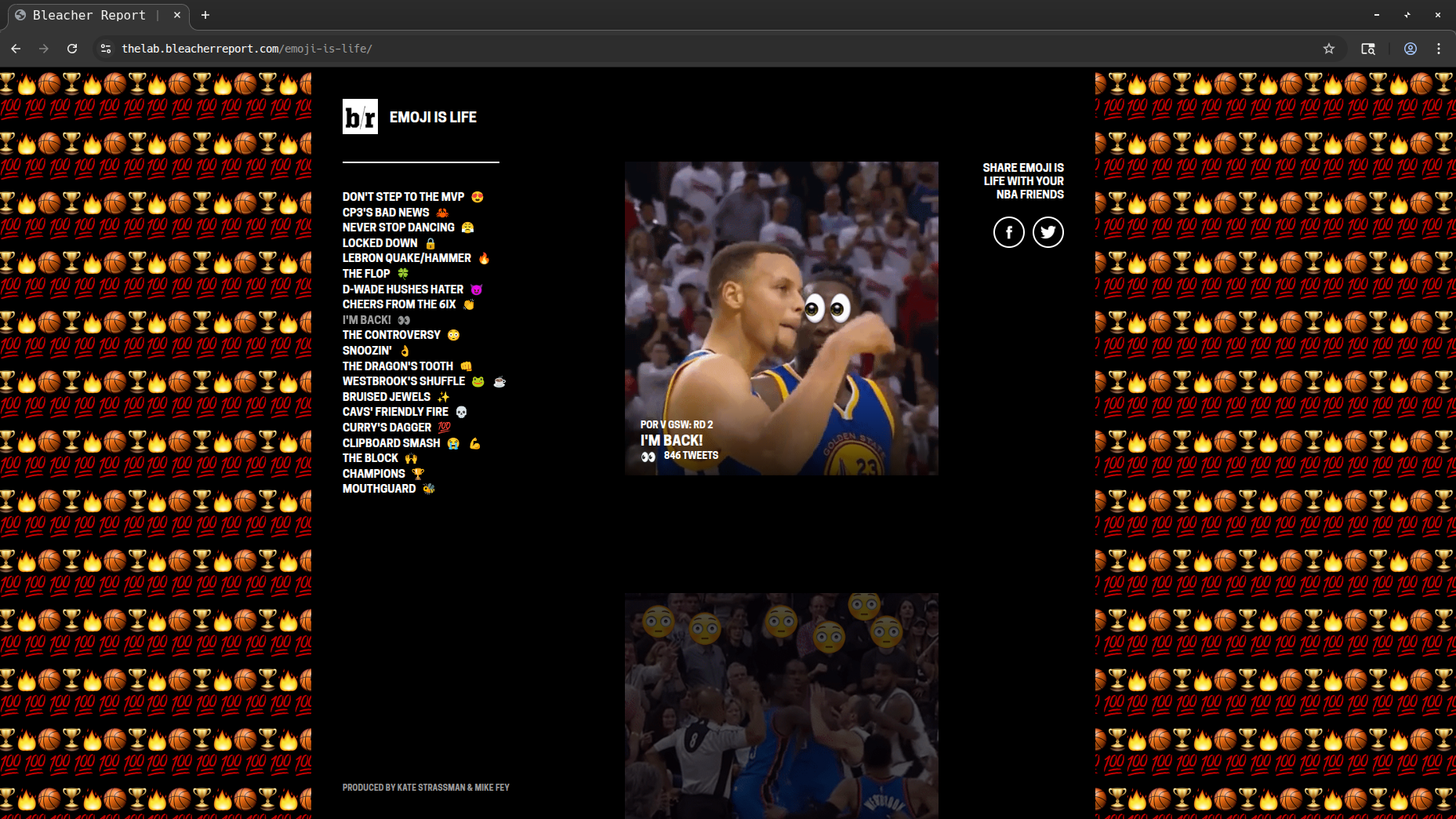
Introduction
I was recently tasked with building a web service which facilitated the creation of Bleacher Report’s Emoji Is Life story: a high-level summary of the 2016 NBA playoffs, as told through emoji.
The service was used during the story’s editorial phase to determine which emoji were being used most frequently when people tweeted during games’ key moments.
A separate service, using Twitter’s Streaming API, was responsible for ingesting tweets sent out during each playoff game – which met a number of qualifications like: @mentioned either/both teams, contained at least one emoji, etc. – and storing them in a database.
My service was then responsible for making that data accessible and digestible to editors, who used it to surface interesting “moments” in each game.
Overview
The service was built using Clojure, Docker, PostgreSQL and deployed to Heroku. The data was exposed via a REST API, built using Ring, which made it possible for editors to interactively explore the different resources: series, games, moments, etc. (e.g. 3700 people authored tweets using the 😳 emoji after Waiters elbowed Ginobili during the Thunder’s win over the Spurs in game 2 of the Western Conference semifinals)
Lessons Learned/Suspicions Confirmed
Docker
Docker and Docker Compose made standing-up the application for development and testing trivial. Once Docker/Compose had been installed and the Dockerfile/docker-compose.yml config files had been authored, everything just worked. New contributors could jump in and have the project running on their machine within minutes.
PostgreSQL/Korma
We used the Korma library to interface with PostgreSQL and it was a pleasure to work with. Korma is a DSL that translates Clojure code into SQL statements. It also does useful things like prevent SQL injection when inserting dynamic values into queries. Korma does require you to write more boilerplate than a more – ahem – active ORM would, but it provides more flexibility as a result.
Here’s the entity definition and series query functions from emoji-api.db:
(defdb db (postgres {...}))
(declare series game emoji)
(defentity series
(table :Series)
(has-many game {:fk :seriesId}))
(defn query-series-plural []
(select series))
(defn query-series-singular [id]
(let [series-id (read-string id)]
(first (select series
(where {:id series-id})
(with game)))))One Korma feature I wish I’d known about while working on this project is set-naming, which allows you to define a top-level strategy for translating non-standard table/column names. The framework used to scaffold the emoji/moment database used capital letters for table names and camel case for column names; instead of having to be cognizant of these quirks when defining entities, we could have defined conversion strategies once in the defdb declaration and used standard Clojure naming conventions throughout:
(defentity series
(table :series)
(has-many game {:fk :series-id}))Data Transformation
In order to make the data digestible for editors, the tweet result set for a given moment was run through a transformation function in order to transform a list of emoji IDs and team IDs into a map containing the top 10 emojis used in reference to each team and both teams.
The data transformation function is as follows:
(defn reduce-emojis [{:keys [winner-id loser-id emojis]}]
"transforms {:emojis [{:emojiId 100 :teamId "cc"}
{:emojiId 200 :teamId "dd"}
{:emojiId 200 :teamId "dd"}
{:emojiId 300 :teamId "both"}]
:loser-id 2
:winner-id 1}
into {"cc" [{:emoji a :emoji-id 100 :count 1}
{:emoji c :emoji-id 300 :count 1}]
"dd" [{:emoji b :emoji-id 200 :count 2}
{:emoji c :emoji-id 300 :count 1}]
"both" [{:emoji a :emoji-id 100 :count 1}
{:emoji b :emoji-id 200 :count 2}
{:emoji c :emoji-id 300 :count 1}]}"
(let [emojis' (r/reduce
(fn [memo member]
(let [emoji-id (:emojiId member)
team-id (:teamId member)
get-new-count (fn [id]
(let [path [id emoji-id]
old-count (if-let [count' (get-in memo path)]
count'
0)
new-count (inc old-count)]
new-count))
new-both-count (get-new-count :both)
new-winner-count (get-new-count winner-id)
new-loser-count (get-new-count loser-id)
new-team-count (get-new-count team-id)]
(if (= team-id "both")
(-> memo
(assoc-in [winner-id emoji-id] new-winner-count)
(assoc-in [loser-id emoji-id] new-loser-count)
(assoc-in [:both emoji-id] new-both-count))
(-> memo
(assoc-in [team-id emoji-id] new-team-count)
(assoc-in [:both emoji-id] new-both-count)))))
{:both {}
winner-id {}
loser-id {}}
emojis)
emojis'' (for [[team-id emojis] emojis']
{team-id (->>
(for [[emoji-id count] emojis]
{:emoji-id emoji-id
:emoji (get emoji-map emoji-id)
:count count})
(sort-by :count >)
(take 10)
(vec))})
emojis''' (into {} emojis'')]
emojis'''))While this transformation function worked well enough, it’s certainly not as efficient as it could have been. (I’ve yet to revisit the implementation, but I believe the entire transformation could be achieved in a single-pass.) I was also working under the (mistaken) impression that r/reduce was automatically parallelized, but that turns out not to be the case. r/fold, among other functions in the Reducers library, are automatically parallelized – when doing so is efficient. This post provides a nice, high-level overview of the Reducers library. Also, be sure to check out the official Reducers docs.
Because this data set wasn’t big, was accessed infrequently and the data transformations were snappy, I didn’t invest any time in caching the transformation results. However, that would have been trivial using either clojure.core/memoize or a more robust solution like core.memoize – which allows for pluggable caches as opposed to using system memory, like clojure.core/memoize does.
Testing
We used Midje to facilitate TDD and I was happy with the results.
Midje states its aims as, “to encourage readable tests, to support a balance between abstraction and concreteness, and to be gracious in its treatment of the people who use it” and I think it does that all quite well.
I found its documentation and examples to be well written and wide-reaching. (The Midje wiki in Github has 96 pages!) The fact(s) structure is ergonomic, self-documenting and provides for nice separation of domain concepts. Its error messages are comprehensible and its “checkers” are very expressive. For instance, here’s an example of the facts for the reduce-emojis function:
(facts "reduce-emojis"
(fact "it transforms a map of malformed emoji and team ids into a map of
well formed team ids containing maps of well formed emoji, emoji
ids and counts"
(let [actual-emojis (reduce-emojis {:winner-id 1
:loser-id 2
:emojis [{:emojiId 1 :teamId 1}
{:emojiId 2 :teamId 2}
{:emojiId 10 :teamId "both"}]})
expected-emojis {1 [{:emoji-id 1
:emoji "😀"
:count 1}
{:emoji-id 10
:emoji "😉"
:count 1}]
2 [{:emoji-id 2
:emoji "😬"
:count 1}
{:emoji-id 10
:emoji "😉"
:count 1}]
:both [{:emoji-id 10
:emoji "😉"
:count 1}]}]
actual-emojis => expected-emojis)))The matcher used in this example (=>) is syntactic sugar for “assert equals” and the same assertion in core/test would look something like: (assert (= actual-emojis expected-emojis)).
Some of Midje’s other checkers are even more expressive.
For example:
=not=>which translates to “assert not equal”=expands-to=>which allows for assertions about macro expansion (!)
Summary
From a technical standpoint, I was quite pleased with how the project came together. There really weren’t any surprises and it was fun to learn more about the Clojure ecosystem.
Most importantly, the editors were happy with the end result and used it to create a unique, insightful and entertaining story.
Update - 11/17/25
Added screenshot of Emoji Is Life page